
Intro
Creating a singing voice using artificial intelligence is an exciting and innovative way to bring music to life. Advances in technology have made AI voices more natural and expressive, allowing for stunning vocal performances without the need for a human singer. Various services are available to create AI singing voices. And in our article we will look at them in detail. These services use artificial intelligence and machine learning algorithms to analyze and simulate human speech patterns, tone, and inflection, resulting in a realistic and dynamic singing voice.
Technical way
To create an AI singing voice, you would typically need a combination of machine learning techniques and audio processing. Here is a general overview of the steps involved:
1. Data collection: Gather a large dataset of high-quality audio recordings of human singers. This dataset will be used to train the AI model.
2. Preprocessing: Clean and preprocess the audio data to remove noise, normalize volume levels, and extract relevant features such as pitch, duration, and timbre.
3. Model training: Use machine learning algorithms, such as deep learning models like recurrent neural networks (RNNs) or convolutional neural networks (CNNs), to train the AI model on the preprocessed audio data. The model should learn to generate singing voices based on the patterns and characteristics present in the training data.
4. Fine-tuning: Fine-tune the trained model using additional techniques like transfer learning or reinforcement learning to improve its performance and make it more expressive.
5. Post-processing: Apply post-processing techniques to enhance the generated singing voice, such as adding effects, adjusting pitch or tempo, or smoothing out any inconsistencies.
6. Evaluation and iteration: Evaluate the quality of the generated singing voice using objective metrics and subjective human feedback. Iterate on the model and training process to improve the results.
It’s important to note that creating a truly convincing AI singing voice is a complex and ongoing research area. While significant progress has been made, achieving a completely indistinguishable AI singing voice from a human singer is still a challenge.

5 popular singing-generated services:
Kits.ai
Kits.ai is marketed as a comprehensive toolbox designed specifically for musicians seeking to create impeccable melodies and symphonies. With Kits, musicians have the ability to fashion their own unique vocal sound, leverage voice models from a community, access celebrity/royalty-free voices, and even utilize AI-powered instruments to fine-tune and perfect their tracks.
This platform encompasses an array of noteworthy features, such as:
- Artist Voice Models with Official Licenses: Kits.ai offers access to officially licensed voice models that have been crafted by renowned artists. Musicians can tap into these models to infuse their compositions with distinctive and recognizable vocal styles.
- Commercial-Use Library: Kits.ai provides a vast library of resources that musicians can employ for commercial purposes. This library includes various elements like sounds, samples, and loops that enhance the creative possibilities for musicians.
- Free AI Voice Model Training: One particularly valuable feature of Kits.ai is the capability to train AI voice models without any cost. Musicians can leverage this functionality to develop customized and personalized voices that align perfectly with their artistic vision.
By combining these features, Kits.ai empowers musicians to experiment, innovate, and create music that is truly unique and captivating.
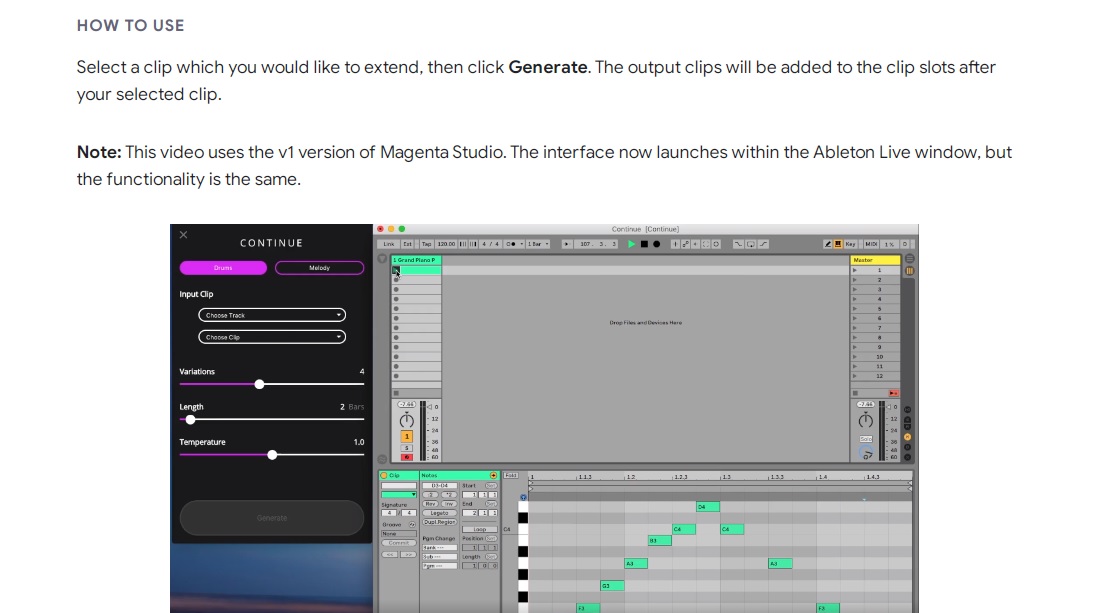
Magenta
Magenta is an open-source research project by Google that explores the intersection of music and machine learning. It offers tools and models for creating AI-generated music, including singing voices. Magenta provides a variety of machine learning models, such as “MelodyRNN” and “Onsets and Frames,” which can be used to generate melodies, harmonies, and even full songs. Users can experiment with these models and create unique compositions with AI-generated singing voices.
Lovo.ai
Genny, developed by LOVO AI, stands out as an incredibly lifelike AI voice generator, attracting a massive user base of over 700,000 individuals. Our all-encompassing toolkit provides both a free version and a premium alternative, ensuring accessibility to a wide range of users.
Even with the free version, users gain access to a comprehensive set of services, including an extensive selection of more than 180 voices available in over 33 diverse languages. Additionally, the features provided are as follows:
Limitless Conversions: Users can convert text into speech without any restrictions, offering unrestricted possibilities for generating voice audio.
Boundless Listening and Sharing: The free version enables users to listen to and effortlessly share their synthesized audio without limitations, fostering seamless collaboration and distribution.
Three Free Downloads Per Month: Users have the privilege of downloading up to three audio files per month at no cost, granting them the freedom to utilize their generated voices in various projects.
Audio File Storage and Sharing: Genny also provides users with the convenience of saving and sharing their audio files, ensuring they can easily access and distribute their synthesized voices whenever needed.
These features collectively establish Genny by LOVO AI as a powerful AI voice generator, forging new possibilities for realistic and diverse vocal synthesis.
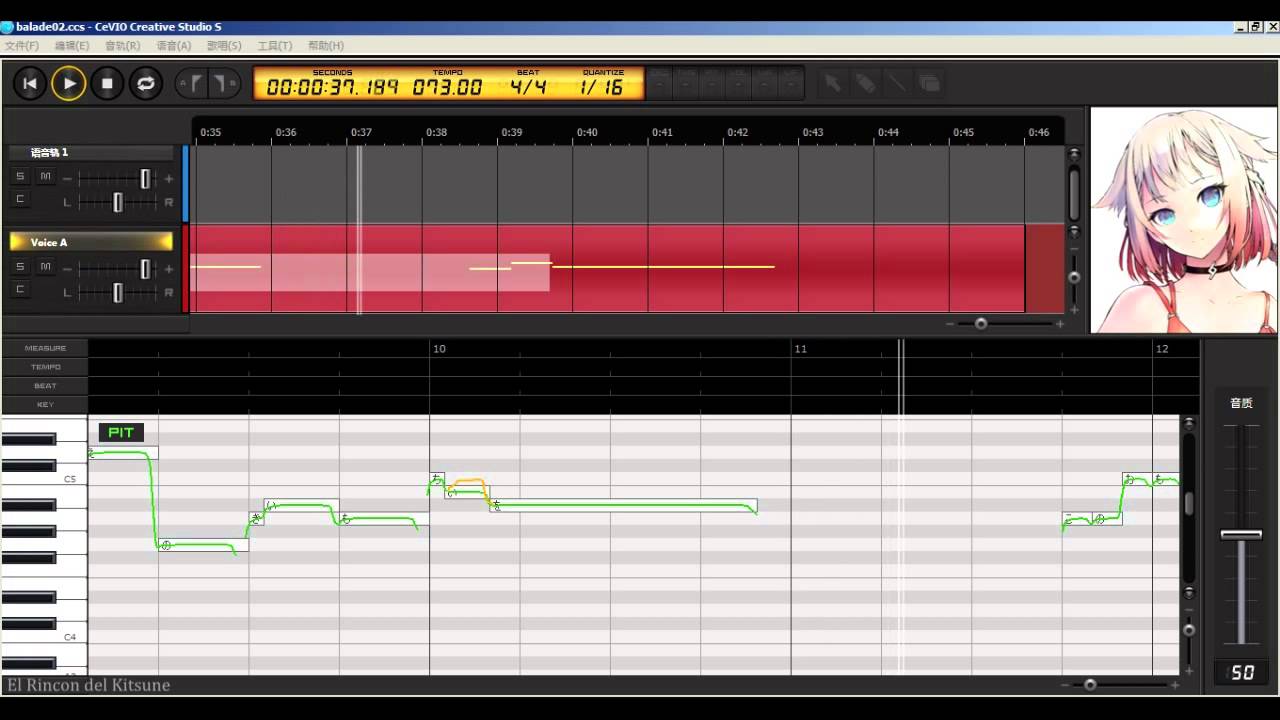
CeVIO
CeVIO is another software synthesizer developed by CeVIO Creative Studio. It allows users to generate AI-driven singing voices and offers a variety of voice banks with different vocal characteristics. CeVIO includes features for controlling aspects like pitch, dynamics, and phonetic expression to fine-tune the generated vocal performances.
Musicfy
Can AI singing voices be customized to imitate specific artists or genres?
Yes, AI singing voices can be customized to imitate specific artists or genres to some extent. While it’s challenging to achieve a perfect imitation, AI models can be trained to learn the nuances of a particular artist’s voice or the stylistic characteristics of a specific genre. Here are a couple of approaches that can be used:
- Voice Transfer
By using voice transfer techniques, AI models can learn the unique features of an artist’s voice and apply them to synthesized singing. This involves training the model on a large dataset of the artist’s songs and using that knowledge to generate AI singing that resembles the artist’s vocal style to some degree.
- Style Transfer
AI models can be trained to adapt their singing style based on the characteristics of a particular genre. For example, the model can be trained on a diverse dataset of songs from the desired genre, learning the specific melodic and rhythmic patterns associated with that genre. This enables the AI model to generate singing that aligns with the chosen genre.
However, it’s important to note that achieving a perfect replication of an artist’s voice or a specific genre is extremely challenging due to the complex and unique nature of human singing. The current state of AI technology can provide impressive imitations, but there may still be limitations in capturing all the subtleties and nuances of a specific voice or genre.
Are there any AI platforms or applications that have successfully imitated specific artists’ voices for commercial use?
Yes, there have been AI platforms and applications that have successfully imitated specific artists’ voices for commercial use. One notable example is the “Deepfake” technology, which utilizes AI to generate highly realistic imitations of voices and faces. While the use of Deepfake technology raises ethical concerns, it has been employed in certain applications. For instance, there have been instances where AI-generated singing voices have been used to imitate deceased artists, allowing their voices to be heard in new compositions or live performances.

It’s important to note that the use of AI-generated imitations of specific artists’ voices for commercial purposes can be subject to legal considerations and copyright issues. Licensing agreements or permissions from the artists or their estates may be required to use their voices in AI-generated commercial projects. Therefore, it is crucial to establish legal and ethical frameworks when utilizing AI platforms or applications for this purpose
In conclusion
Making an AI singing voice has endless possibilities and advantages. It offers control, versatility, and efficiency, making it a valuable tool for musicians, producers, and even content creators. With the constant advancements in AI technology, we can expect to see even more realistic and expressive vocal performances in the future.




